 Yubeen
Yubeen 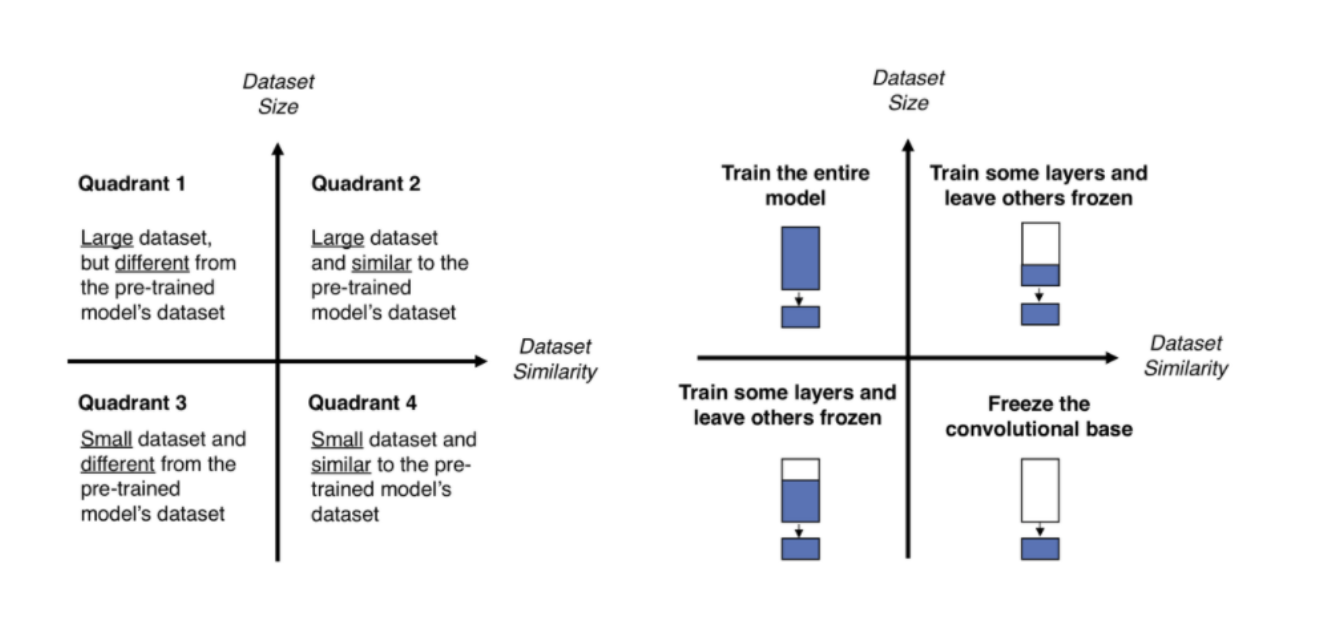
Transfer learning vs Fine-tuning
-
Transfer learning
사전 학습된 모델을 가져와서 freeze를 시킨 후, 새로운 layer를 freeze된 곳 위에 쌓아 그 layer를 새로운 데이터셋에 대해서 학습시키는 과정
-
Fine-tuning
weight 전체 또는 일부만을 freeze한 후 새로운 데이터셋에 대해서 작은 learning rate로 학습을 진행하는 것
Fine-tuning Transfer-Learning Freezing 1) 추가된 layer를 제외하고 Freeze
2) 많이 freeze
3) 약간만 freeze
4) 모두 freeze 안시키기마지막 layer를 제외하고는 전체 freeze Learning Rate Small 관계 없음 Example LLM에서 나의 task에 맞게 변형
- 더 어려운 task가 아니라 더 많은
데이터로 학습된 것을 기초로 조금씩 수정ImageNet에 대한 1000개 분류를
특정 class에 대해서만 더 학습시킬 때
- 이미 더 어려운 task에 대해서 학습됨
1. Large dataset, but different from the pre-trained model’s dataset
이 경우에는 dataset이 크기 때문에 모델 전체를 다시 학습. 아예 새로운 model을 만들 수도 있지만, transfer learning의 성능이 더 좋음.
2. Large dataset, and similar to the pre-trained model’s dataset
이 경우에는 dataset이 많아 앞단의 layer도 같이 학습을 시켜도 overfitting이 발생하지 않음. 따라서 앞단도 같이 학습시킨다. 하지만 dataset이 simillar하기 때문에 굳이 전체를 학습시킬 필요는 없음.
3. Small dataset, and different from the pre-trained model’s dataset
제일 어려운 문제.. 적은 layer를 fine-tuning 하기에는 dataset이 similar하지 않고, 그렇다고 많은 layer를 학습시키면 dataset이 작기 때문에 overfitting이 됨.
4. Small dataset, and similar to the pre-trained model’s dataset
지금 현재 antibody-antigen complex fine-tuning 상황임. 이 경우에는 앞과 마찬가지로 전체 network에 대해 fine-tuning할 경우에는 overfitting 문제가 발생함. 따라서 최종 FC layer에만 fine-tuning 진행 (LR은 1/10로 줄임, learning rate가 높을 경우에 기존에 있던 정보들은 새로운 dataset에 맞춰 새로 update).. RoseTTAFold에는 어떤 식으로 적용해야 할지 모르겠음. 전체적인 layer를 따라서 학습이 진행되기 때문..
Image classification 문제 같은 경우에는 CNN으로 feature를 뽑아내고 마지막 FC layer를 fine-tuning하는 건데 우리 문제에는 적용하기 힘들 것 같다.
Fine-tuning 할 때 주의사항
- Learning rate를 작게 설정해야 한다. (1/10 정도)
- SGD와 같은 안정성 있는 optimizer를 이용한다.
- bottleneck feature만 저장하여 FC layer 만을 학습시키면 학습 시간이 절약된다.
- 모든 layer는 한번 이상 학습이 완료된 상태여야 한다. (random한 weight인 경우에는 기존 네트워크의 가중치를 너무 많이 바꿈)
Model Compression
References
- https://towardsdatascience.com/transfer-learning-from-pre-trained-models-f2393f124751
-
https://velog.io/@xuio/Transfer-Learning과-Fine-Tuning
- https://inhovation97.tistory.com/31
- https://velog.io/@chy0428/DL-Transfer-learning
- https://blog.est.ai/2020/03/딥러닝-모델-압축-방법론과-bert-압축/
- http://mitchgordon.me/machine/learning/2019/11/18/all-the-ways-to-compress-BERT.html
 Structural insight into T cell coinhibition by PD-1H (VISTA)
Structural insight into T cell coinhibition by PD-1H (VISTA)